
OpenAI запідозрили в маніпуляціях із тестами потужної ШІ-моделі o3
У грудні минулого року OpenAI презентувала велику мовну модель o3, заявивши, що вона здатна впоратися з понад 25% набору складних математичних завдань FrontierMath, тоді як інші ШІ-моделі впоралися лише з 2% завдань із цього набору. Однак розбіжності між результатами внутрішніх і незалежних тестів викликали питання про прозорість компанії та практику тестування нейромереж.

На момент анонсу ШІ-моделі o3 представник компанії особливо наголосив на результатах алгоритму під час розв'язання завдань FrontierMath. Однак випущена минулого тижня споживча версія алгоритму далеко не так добре справляється з обчисленнями. Це може вказувати на те, що OpenAI або завищила результати тестування, або в ньому була задіяна інша, більш здатна до розв'язання математичних задач версія o3.
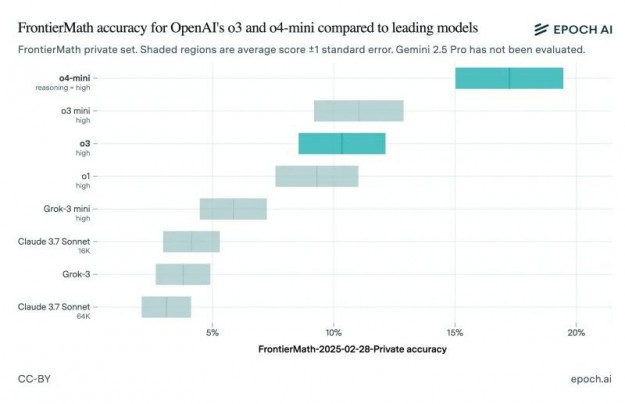
Дослідники з Epoch AI, що стоять за створенням FrontierMath, опублікували результати незалежних тестів загальнодоступної версії ШІ-моделі o3. Виявилося, що алгоритм зумів впоратися тільки з 10 % завдань, що значно нижче заявлених OpenAI 25 %. Разом із цим дослідники протестували ШІ-модель o4-mini, більш компактний і дешевий алгоритм, який є наступником o3-mini.
Звісно, розбіжність у результатах тестування не означає, що OpenAI навмисно завищила показники ШІ-моделі. Нижня межа результатів тестування OpenAI практично збігається з результатами, отриманими Epoch AI. В Epoch AI також зазначили, що модель, яку вони тестували, найімовірніше, відрізняється від тієї, яку тестувала OpenAI. Також зазначається, що дослідники задіяли оновлену версію набору завдань FrontierMath.
«Різниця між нашими результатами і результатами OpenAI може бути пов'язана з тим, що OpenAI оцінює результати за допомогою потужнішої внутрішньої версії, використовуючи більше часу для обчислень, або тому, що ці результати було отримано на іншій підмножині FrontierMath (180 завдань у frontiermath-2024-11-26 проти 290 завдань у frontiermath-2025-02-28)», - сказано в повідомленні Epoch AI.
За даними організації ARC Foundation, яка тестувала попередню версію o3, публічна версія ШІ-алгоритму «є іншою моделлю», яка оптимізована для використання в чаті/продуктах. «Обчислювальний рівень усіх випущених версій o3 нижчий, ніж у версії, яку ми тестували», - сказано в повідомленні ARC.
Сотрудница OpenAI Венда Чжоу (Wenda Zhou) рассказала, что публичная версия o3 «более оптимизирована для реальных случаев использования» и повышения скорости обработки запросов по сравнению с версией o3, которую компания тестировала в декабре. По её словам, это и является причиной того, что результаты тестирования в бенчмарках могут отличаться от того, что показывала OpenAI.
Співробітниця OpenAI Венда Чжоу (Wenda Zhou) розповіла, що публічна версія o3 «більш оптимізована для реальних випадків використання» та підвищення швидкості опрацювання запитів порівняно з версією o3, яку компанія тестувала в грудні. За її словами, це і є причиною того, що результати тестування в бенчмарках можуть відрізнятися від того, що показувала OpenAI.
Джерело: SmartPhone.ua
Обговорення новини
Попередні новини
 Чат-боти все краще пізнають людей: Grok Ілона Маска тепер пам'ятає всі ваші розмови22:03 17.04.2025
Чат-боти все краще пізнають людей: Grok Ілона Маска тепер пам'ятає всі ваші розмови22:03 17.04.2025Штучний інтелект Grok, розроблений компанією xAI Ілона Маска, отримав нову функцію: тепер він здатний запам'ятовувати попередні розмови з користувачами.
 Anthropic готує конкурента голосовому режиму ChatGPT22:50 16.04.2025
Anthropic готує конкурента голосовому режиму ChatGPT22:50 16.04.2025Компанія Anthropic, заснована колишніми співробітниками OpenAI, готується представити нову функцію voice mode, яка може скласти конкуренцію аналогічній опції в ChatGPT від OpenAI, повідомляє Bloomberg.
 Краща за GPT-4o «майже за всіма параметрами»: OpenAI представила флагманську ШІ-модель GPT-4.112:27 15.04.2025
Краща за GPT-4o «майже за всіма параметрами»: OpenAI представила флагманську ШІ-модель GPT-4.112:27 15.04.2025OpenAI офіційно представила велику мовну модель GPT-4.1, яка є наступником випущеного торік мультимодального алгоритму GPT-4o. За даними компанії, нова ШІ-модель отримала контекстне вікно більшого розміру і загалом перевершує GPT-4o "майже за всіма параметрами".


